Получать картинки будем из кеша chrome. Наша задача состоит не только в том, чтобы выдернуть картинки из кеша браузера, но и перевести их из формата webp в jpg, отресайзить до 100px по сторонам, удалив из них не пропорциональные, а именно те, где ширина или высота менее/более 15% от 100px. А затем окончательно отресайзим их до пропорции 100×100 пикселей.
ChromeCacheView — простенькая утилитка, которая позволит нам получить линки на файлы картинок в сети. Чистим весь кеш в браузере, открываем страницу выдачи картинок, мотаем вниз нужное нам приблизительно кол-во. Открываем программку, в опциях оставляем только картинки и сортируем по дате доступа.
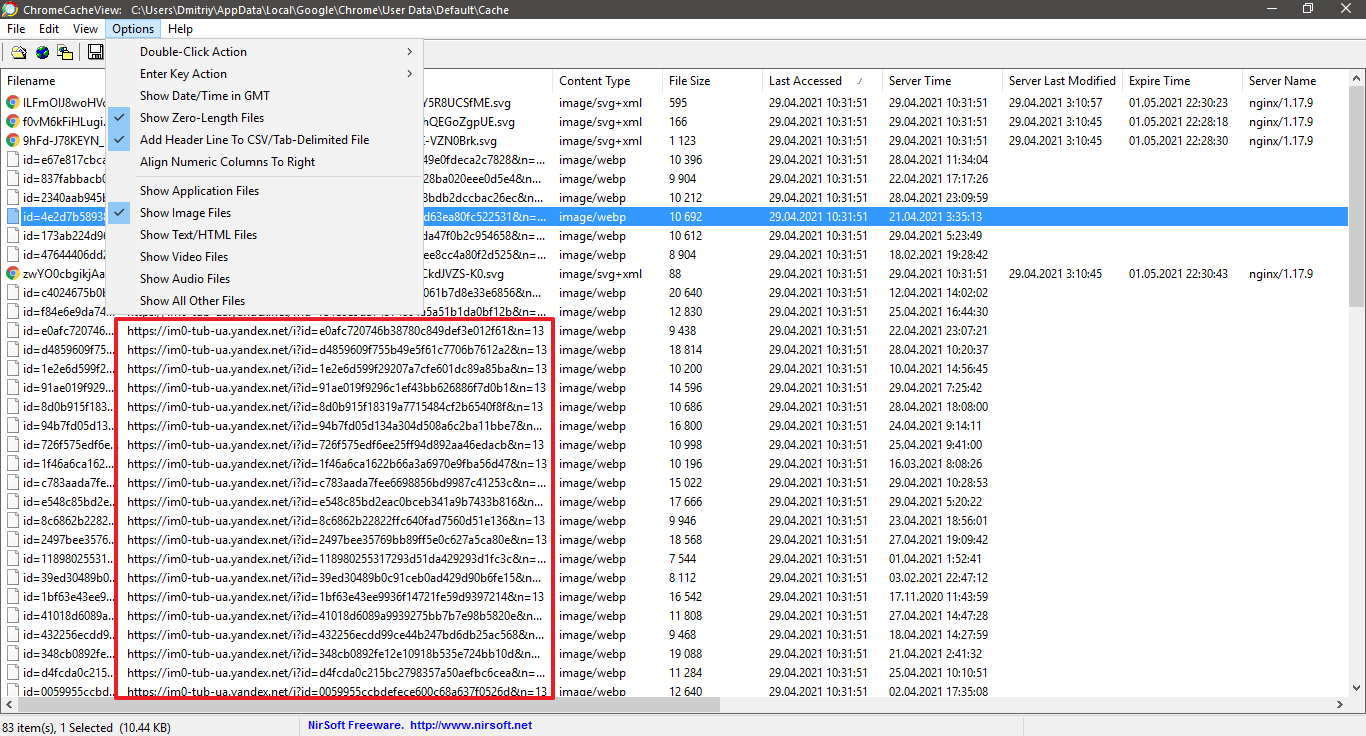
К сожалению, остальных фильтров покруче тут нет, поэтому не мудрствуя лукаво, выделяем все записи и копируем все url что выдала программа. Для этого: CTRL+A и CTRL+U
Вставляем url в текстовый файлик и сохраняем его.
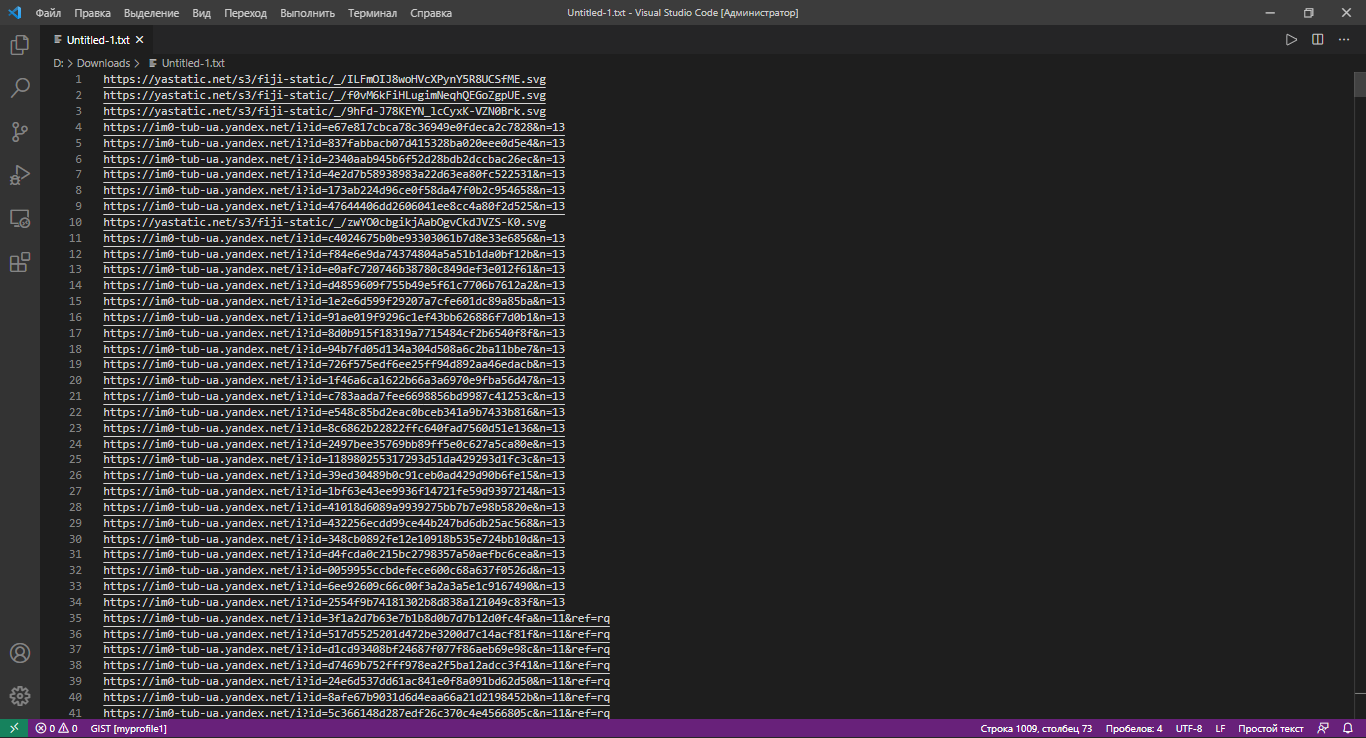
Грепнем по созданному файлу в новый файл только то, что необходимо по шаблону:
grep '^https://im0-tub-ua.yandex.net/i?id=' Untitled-1.txt > url.txt
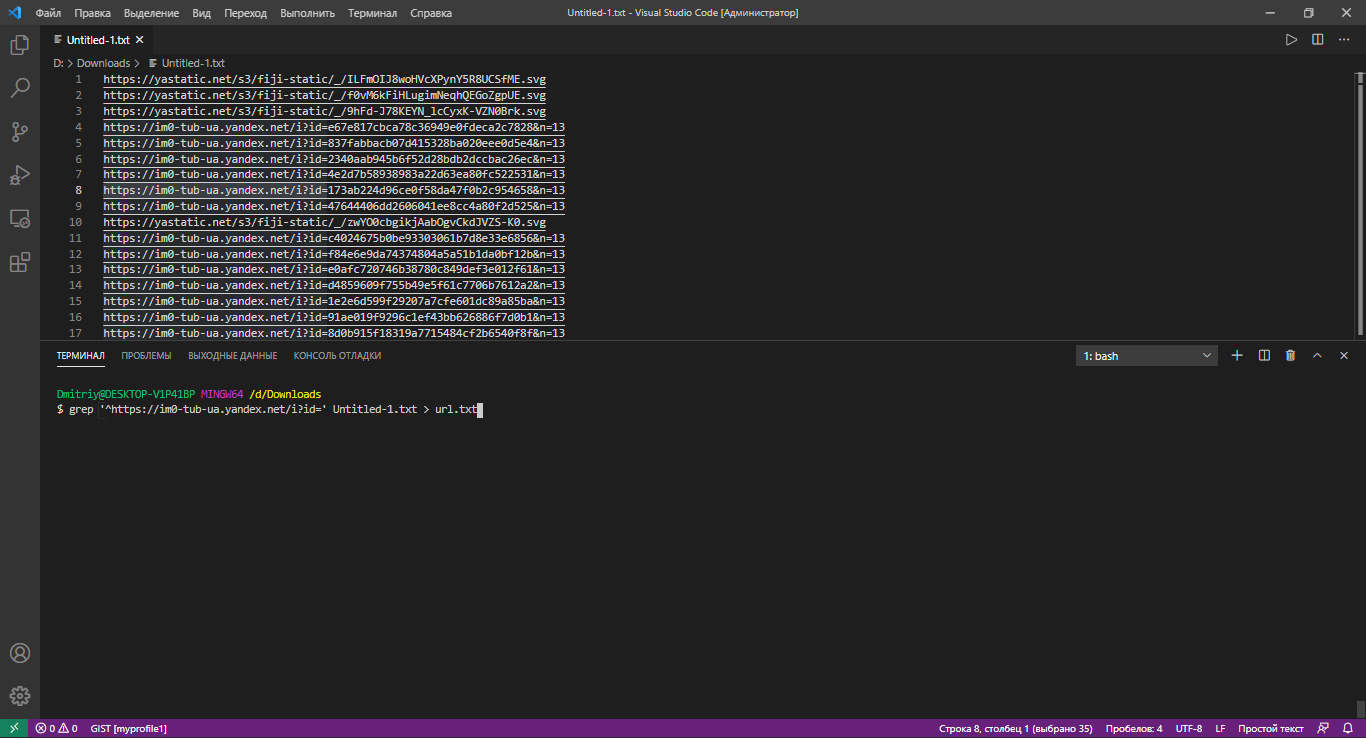
С вновь созданным файлом url.txt идём на linux систему и остальные действия выполним уже на ней.
Командная строка, ваш выход:
# создаём временный каталог
mkdir images
# скачиваем url сохраняя тот порядок в котором получен список
i=0;while read url; do ((i++)) ; wget -qO- $url > images/$i.webp ; done < url.txt
# конверим webp в jpg с ресайзом одной из сторон до 100 пискселей
# и удаляем ненужные более webp файлы
for file in images/* ; do convert $file -resize 100 $file.jpg ; rm $file ; done
# определяем не подходящие под пропорции сторон +/- 15% и удаляем их
for file in images/*; do i=$(identify -ping -format '%w %h' $file | awk '$1/$2<0.85||$1/$2>1.15{print $1/$2}') ; if [ -n "${i}" ]; then rm $file ; fi ; done
# переходим в каталог
cd images/
# делаем окончательный ресайз, сохраняем картинки по порядку и удаляем временный файл
i=0;for file in $(ls | sort -n) ; do ((i++)) ; convert $file -resize 100x100! $i.jpg ; rm $file ; done
# заворачиваем в архив
zip ../images.zip ./*
# выходим и удаляем временный каталог
cd .. && rm -r images
Готово.
UPD: все манипуляции выше, можно сделать одной командой. Для этого накатал специальный скрипт под Linux: https://github.com/avtobys/ava_parser
- Чистим полностью кеш в лисе
- Открываем выдачу яндекса и мотаем вниз заполняя кеш
- Запускаем команду указанную в readme
- Указываем любое имя для zip архива
- Complete!